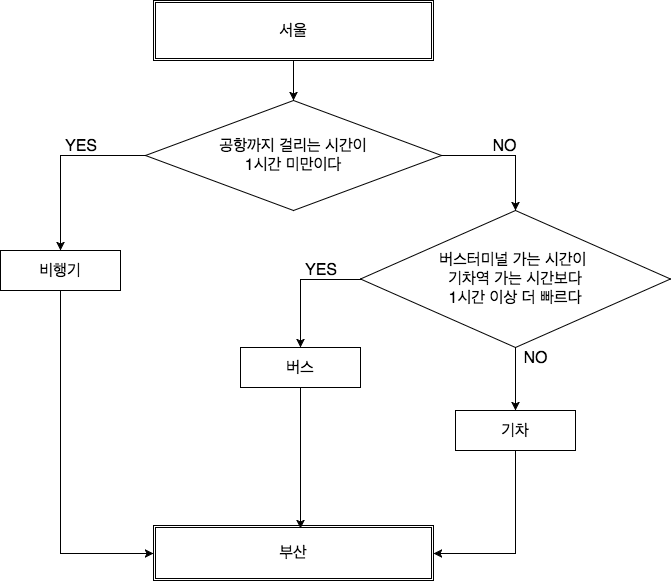
랜덤 포레스트(random forest)와 그라디언트 부스팅(gradient boosting)은 둘 다 기계 학습에 사용되는 앙상블 학습 알고리즘입니다. 둘 다 의사결정 트리를 기반으로 하며 분류 및 회귀 문제에 사용됩니다. 단, 이 두 가지에 의사결정 트리 앙상블을 생성하는 접근 방식이 다릅니다.랜덤 포레스트 알고리즘은 분류(classification)에서 다수결을 취하거나 회귀(regression)로 평균화하여 여러 의사결정 트리를 구축하고 출력을 결합하여 판단합니다. 이러한 의사결정 트리는 변수 및 훈련 데이터 샘플의 임의의 서브셋을 사용하여 구성되므로 이름은 “랜덤” 포레스트’입니다. 아이디어는 트리에서 다양성을 생성함으로써 오버핏을 줄이고 모델의 성능을 향상시키는 것입니다.

한편, 그라디언트 부스팅은 몇 가지 약한(weak) 학습 모델을 결합하여 강력한 학습자를 만드는 부스팅 알고리즘입니다. 랜덤 포레스트와 달리 그라디언트 부스팅은 의사결정 트리를 순차적으로 구축하며, 각각의 새로운 트리는 이전 트리의 오류를 수정하도록 훈련됩니다. 기울기 강하 알고리즘은 예측치와 실제 값의 차이를 나타내는 손실 함수를 최소화하는 데 사용됩니다. 손실 함수를 줄임으로써 모델의 예측력이 서서히 향상됩니다.

요약하자면 랜덤 포레스트와 글래디언트 부스팅의 주요 차이점은 랜덤 포레스트가 독립적으로 여러 트리를 생성하는 반면 글래디언트 부스팅은 이전 트리의 정보를 사용하여 다음 트리의 구성을 안내하여 트리를 순차적으로 구성한다는 것입니다. 그라디언트 부스팅은 일반적으로 랜덤 포레스트보다 계산 능력이 더 많이 요구되지만 복잡한 데이터 세트를 처리할 때 더 나은 정확도를 제공할 수 있습니다.머신러닝이 뛰어난 통계 전문 소프트웨어인 Minitab을 이용하면 예측 분석을 보다 쉽게 할 수 있습니다. https://www.minitab.com/ko-kr/products/minitab/ # 보다 다양한 내용은 https://blog.naver.com/jiehyunkim 에서 보실 수 있습니다.
인기글

![[서울소셜리딩그룹] 토요포럼 505회 - 이경종 대표의 '인공지능 관련 주요 법안 발의 현황 및 정책'과 정종현 교수의 '채팅 GPT에서 시작된 초거대 AI 시대' 리뷰](https://t1.daumcdn.net/cfile/tistory/997DB13D5D56122D05 "[서울소셜리딩그룹] 토요포럼 505회 - 이경종 대표의 '인공지능 관련 주요 법안 발의 현황 및 정책'과 정종현 교수의 '채팅 GPT에서 시작된 초거대 AI 시대' 리뷰")